
|
 13 September 2021, 22:24
13 September 2021, 22:24
|
#1 |
|
Registered User
Join Date: Apr 2013
Location: paris
Posts: 133
|
Is there a better packer than arjm7?
Hi!
I recently released my LDOS Amiga trackload demo toolchain ( https://github.com/arnaud-carre/ldos ). Since my Atari version I always used Arj -m7 as data packer. It has very good packing ratio and reasonable depacking speed (can depack at floppy disk bandwidth) This packer is maybe 20 years old now and I was investigating other packers to find a better one. But it seems I failed ( Please note I'm not talking about arithmetic coding packers like packfire-lzma or crinckler. Both are excellent packers (and awesome packing ratio) but decoding speed doesn't suit for LDOS. So I'm talking about all LZxx packers family.) I tested:
These three packers has almost the same packing ratio, sometimes better than arjm7 but sometimes worst. So as a test, I'm using my "shrinked on a floppy to death" demo: AmigAtari ( https://www.pouet.net/prod.php?which=85276 ). I also tested to re-build De Profundis demo ( https://www.pouet.net/prod.php?which=81081 ). And for both demos, all three packers have worst packing ratio than arjm7. ( for instance AmigAtari demo can't fit on floppy with any of these 3 packers) So my question: any of you knows another packer I could test to replace Arjm7? (btw Arjm7 is nice, my issue is that no one have the packer source code, so I would prefer to have integrated compression code in my toolchain ) |

|
|
13 September 2021, 22:41
|
#2 |
|
Going nowhere
Join Date: Oct 2001
Location: United Kingdom
Age: 50
Posts: 9,016
|
Shrinkler is likely better, but on 68000 for large files its slooooooooooowwwwwwwww.
Small files it might be tolerable |
|
|
|
13 September 2021, 22:58
|
#3 |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
I've never found any on the Amiga, but potentially something better than ARJm7 could be done.
Main idea could be to substitute huffman stage with tANS and do something for repeating LZ codes. I've also somewhere a modified version of apLib based on exhaustive parsing (with no source available..) and a different bitcode (made by me), but packing ratio is very similar to apultra. I too had brutally integrated ARJm7 into my loader, but in a completely impromptu and dedicated way, your code will probably be at least readable and commented, I'll check it. 
|
|
|
|
14 September 2021, 18:38
|
#4 |
|
Registered User
Join Date: Dec 2011
Location: Gummersbach
Posts: 18
|
You should try zx0: https://github.com/einar-saukas/ZX0
|
|
|
|
14 September 2021, 19:23
|
#5 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
 I looked at the decompressor and the documentation very quickly. I doubt this compressor will be as effective as the ARJm7, but it has to be tested in the field. First of all it is a pure LZ one and it has a big self-limitation for the 68k architecture: the maximum offset for a matches is 64k. But the reported performance figures on packing ratio are excellent! The data encoding is not exactly 68k friendly, it should be changed. But is very simple and could potentially be very very fast in decompression. It contain one of the ideas I mentioned above: the repetition of the last LZ offset. If I'll find the time, however, I'll do some tests. EDIT: following the link you will find some discussions and a lot of interesting information! (mainly for 8-bit processors) Last edited by ross; 14 September 2021 at 20:57. |
|
|
|
|
14 September 2021, 21:20
|
#6 | |
|
Registered User
Join Date: Apr 2013
Location: paris
Posts: 133
|
Quote:
|
|
|
|
|
14 September 2021, 21:57
|
#7 |
|
Registered User
Join Date: Dec 2011
Location: Gummersbach
Posts: 18
|
zx0 packs better than aplib on nearly all files I tested so far. Maybe you give it a try?
|
|
|
|
15 September 2021, 01:05
|
#8 | |
|
Registered User
Join Date: Apr 2013
Location: paris
Posts: 133
|
Quote:
zx0 beats arj7 for these 3 files! that's quite amazing if you consider how the depacker is simple. I have to double check that with all the data of AmigAtari demo tomorrow, but it's very promising! |
|
|
|
|
15 September 2021, 01:07
|
#9 |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
With small files seems very good and from the few tests I made it usually beat the 'LZ only' packers available on the Amiga.
The compression is very slow so put it to work in the background and do something else  But as I thought for large files it suffers a lot from limited LZ distances: zx0.exe Zombies.SHP File compressed from 245720 to 50553 bytes. Result with other packers: https://eab.abime.net/showpost.php?p...3&postcount=24 Best is nrv2r at 46238 bytes. Ok ok the result for a single 'big' file doesn't make any sense, but I already had results to compare (and it took to compress several minutes, so that's enough for now ).
|
|
|
|
15 September 2021, 01:13
|
#10 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
In my opinion also a lot can be done to improve the decompression speed for 68k (with different bitcoding). And I also want to try it with greater LZ distances. But the big slowness in compression scares me a bit.. |
|
|
|
|
15 September 2021, 01:26
|
#11 | |
|
Registered User
Join Date: Apr 2013
Location: paris
Posts: 133
|
Quote:
|
|
|
|
|
15 September 2021, 01:32
|
#12 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
Maybe a -q version with large LZ offsets could be a nice compromise. EDIT: zx0.exe -q -f Zombies.SHP File compressed from 245720 to 59796 bytes! ... But is fast
|
|
|
|
|
15 September 2021, 03:47
|
#13 |
|
Registered User
Join Date: Jun 2016
Location: europe
Posts: 1,054
|
That compression speed
 . Took ~5min for a 146KB file. . Took ~5min for a 146KB file.Other than that, it looks *very* good. Great combination of speed and ratio: 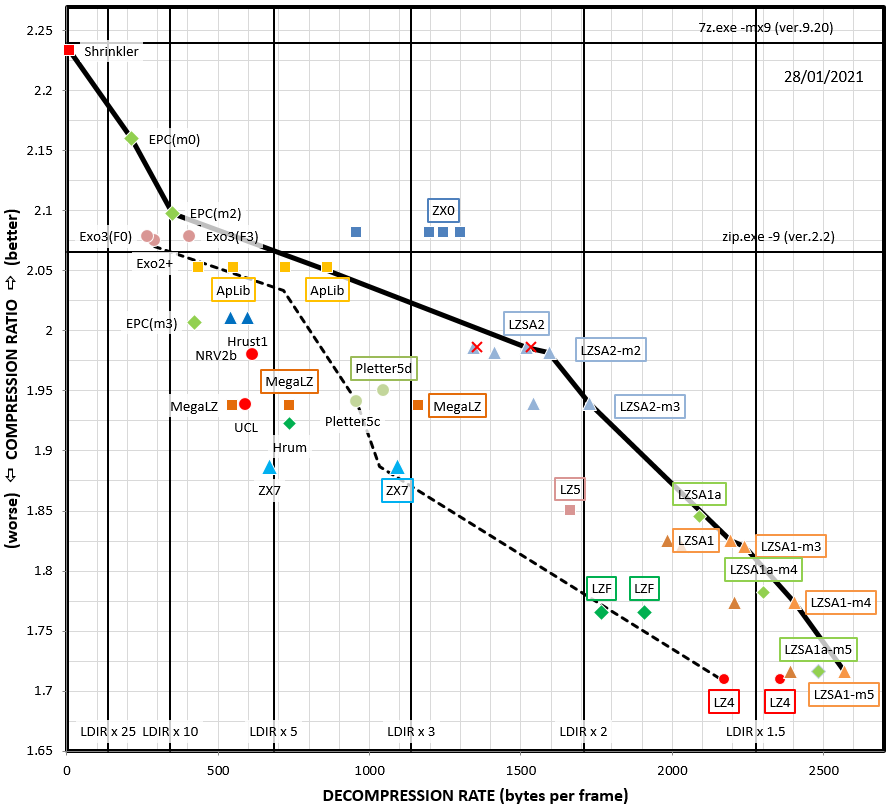 Beats nrv2b in ratio, and is between lz4 and nrv2b in speed. I'll have to do more tests to see how fast it is compared to custom nrv2b and lz4, and whether it can replace both with a single strike (lzsa looks good on the lz4 side of things, so more new stuff for me to check out... rip lz4). |
|
|
|
15 September 2021, 08:55
|
#14 |
|
Registered User
Join Date: Dec 2011
Location: Gummersbach
Posts: 18
|
We're using an optimized version by Soci for our c64 productions. It packs a lot faster. You can find it here with slightly changed format: https://github.com/bboxy/bitfire Maybe it can be improved for larger files > 64kb which should improve compression.
|
|
|
|
15 September 2021, 11:10
|
#15 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
I've some figures for the speed (Zombies.SHP file, 240KiB): - original version: TotalMinutes 14,95 - 'bitfire' version: TotalMinutes 10,46 So this version is sure faster, but in the same magnitude, so do not expect a life changer Remarks: Original ZX0 seems compiled with 32-bit Open Watcom C, I haven't recompiled the sources. I compiled the 'bitfire' version with GCC11.2 (-O3, in 32-bit mode to be a little more fair, it's probably a bit faster if compiled in native 64-bit). Code from repository do not compile straight away because it lack an header file, but it is related to sfx support so the related code can be removed without problems (but it must be reported to Tobias). About the maximum reachable LZ offset: it's hardcoded to MAX_OFFSET_ZX0 32640 Of course it can't be modified like it was nothing, because there is an overflow in bitcoding, so you have to work a little to see the effects of a change in that case (at least 'virtualize' a new bitcoding). |
|
|
|
|
15 September 2021, 11:17
|
#16 |
|
Registered User
Join Date: Dec 2011
Location: Gummersbach
Posts: 18
|
There's no header missing. You'll need ACME assembler in the build chain for the c64 sfx support. You can remove the sfx support as you did or add Amiga sfx support.
|
|
|
|
15 September 2021, 11:28
|
#17 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
#include "sfx.h" compiler stop, and I had to manually remove the sfx code. Not a problem at all, but maybe a check for the conditional compilation of that part would be useful (for a casual user like me which does not use the sfx part )
|
|
|
|
|
15 September 2021, 14:32
|
#18 | |
|
Registered User
Join Date: May 2013
Location: Grimstad / Norway
Posts: 852
|
Quote:
|
|
|
|
|
15 September 2021, 15:16
|
#19 |
|
bye
Join Date: Jun 2016
Location: Some / Where
Posts: 681
|
 hm... |
|
|
|
15 September 2021, 15:27
|
#20 | |
|
Defendit numerus
Join Date: Mar 2017
Location: Crossing the Rubicon
Age: 54
Posts: 4,488
|
Quote:
This usually works because the data is sub-related in some way (like arrays or tables). EDIT: normally the offsets are the most 'annoying' part of the pair, because while the probability of the 'length' part follows an inverse proportionality law, the distance can have any value, so it is convenient to be able to reuse it without re-encoding it. Entropy encoders can extend this concept saving LZ stuff in a selectable bucket, extending the 'natural' 256 symbols alphabet. Experience shows that the larger the cache size, the lower the added gain, until it is counterproductive. LZMA uses n=4 and LZX n=3, but I'm just going to memory. Many compressors (like nrv2) use n=1, because it is very simple to manage and give good results. ZX0 uses n=1 in a very clever way. Last edited by ross; 15 September 2021 at 15:55. |
|
|
|
| Currently Active Users Viewing This Thread: 1 (0 members and 1 guests) | |
| Thread Tools | |
 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| Zip packer corrupting files ? | Retroplay | support.Apps | 13 | 23 July 2011 12:17 |
| old soundeditors and pt-packer | Promax | request.Apps | 7 | 14 July 2010 13:21 |
| Pierre Adane Packer | Muerto | request.Modules | 15 | 21 October 2009 18:03 |
| Power Packer PP Files HELP | W4r3DeV1L | support.Apps | 2 | 30 September 2008 06:20 |
| Cryptoburners graphics packer | Ziaxx | request.Apps | 1 | 06 March 2007 10:30 |
|
|




