
|
 01 May 2021, 10:54
01 May 2021, 10:54
|
#21 | |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
Quote:
Code:
pi-amiga number ? calculator v9 (68000) number of digits (up to 9248)? 100 314... .10 Code:
pi-amiga number ? calculator v9 (68000) number of digits (up to 9248)? 1000 314... 4.40 Code:
pi-amiga number ? calculator v9 (68000) number of digits (up to 9248)? 3000 314... 34.16 Code:
pi-amiga1200 number ? calculator v9 (68020) number of digits (up to 9252)? 100 314... .12 Code:
pi-amiga1200 number ? calculator v9 (68020) number of digits (up to 9252)? 1000 314... 4.42 Code:
pi-amiga1200 number ? calculator v9 (68020) number of digits (up to 9252)? 3000 314... 34.42 The time results vary a bit between runs, most likely due to multitasking and perhaps accuracy of the frame counter, on the first "100" test I get results between 0.09 and 0.12 running the same program. I attached a screenshot, quality kind of sucks, it's hard to get good ones from CRT screens (looks better in reality). Last edited by BippyM; 01 June 2021 at 18:24. |
|

|
|
01 May 2021, 12:06
|
#22 | |||||
|
Registered User
Join Date: Aug 2010
Location: Italy
Posts: 787
|
Quote:
 ). ).Quote:
Quote:
Quote:
Quote:
Code:
divu.w d4,d6 bvs.s .longdiv move.l d6,d7 clr.w d6 eor.l d6,d7 swap.w d6 move.w d6,(a3) Code:
divu.w d4,d6 bvs.s .longdiv move.l d6,d7 clr.w d6 eor.l d6,d7 move.l d6,(a3) swap.w d6 |
|||||
|
|
|
01 May 2021, 12:57
|
#23 | |||
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
 Quote:
 However your optimization just replaces MOVEQ and MOVE.W with MOVE.L and EOR.L and IMHO your pair is even a bit slower. However your optimization just replaces MOVEQ and MOVE.W with MOVE.L and EOR.L and IMHO your pair is even a bit slower.Quote:
|
|||
|
|
|
01 May 2021, 13:57
|
#24 | ||
|
Registered User
Join Date: Aug 2010
Location: Italy
Posts: 787
|
Quote:
That said, after an instruction that writes to memory, the CPU can enjoy many "free" cycles for the cached non-memory instructions; for example, I measured that after a write to CHIP RAM, the 68030 on my Blizzard 1230-IV has 26 free cycles which can be used for all the instructions that fit in those cycles; during a write to FAST RAM (which the CPU has exclusive access to and is no-wait-state) the CPU has 4 free cycles. (Exception: if I remember correctly - it's been a while - rotate and, maybe, also shift instructions, for some strange reason, actually can't benefit from the free cycles and cause the CPU to stall until the write finishes.) This is the reason why I proposed the longword write trick. Quote:
 Basically, my code does not add cycles, but it eliminates a register dependency, thus actually making the code faster on the 68060. Basically, my code does not add cycles, but it eliminates a register dependency, thus actually making the code faster on the 68060.
Last edited by saimo; 01 May 2021 at 14:03. |
||
|
|
|
01 May 2021, 18:53
|
#25 | |||
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
pi-amiga-8 - an old version (68000) pi-amiga-8mo - an old version with MULUopt=1 (68000) pi-amiga-9 - BVS optimization (68000) pi-amiga-9mo - BVS optimization with MULUopt=1 (68000) pi-amiga1200-8 - an old version (68020) pi-amiga1200-8mo - an old version with MULUopt=1 (68020) pi-amiga1200-9 - BVS optimization (68020) pi-amiga1200-9mo - BVS optimization with MULUopt=1 (68020) You have already run pi-amiga-9mo and pi-amiga1200-9mo - if you rerun them the results must be the same. So results for pi-amiga-8, pi-amiga-8mo, pi-amiga-9, pi-amiga1200-8, pi-amiga1200-8mo, pi-amiga1200-9 are only required to get information which optimization actually works on the 68020. This time only 3000 digit results are required. Quote:
Quote:
The 68060 based Amiga would have been quite good until maybe 1998. But now I have large problems even with the 68020 optimization... I doubt that I can discover how to optimize the code even for the 68030 - I will need help from Atari people for this. So the 68060 optimization is rather among pure fantastics for me now.
Last edited by BippyM; 01 June 2021 at 18:24. |
|||
|
|
|
02 May 2021, 11:23
|
#26 |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
While waiting for new electrolytic capacitors to ship for my original A1200 PSU (it needs recapping), I have connected a PC ATX 250W power supply temporarily which gives me more options.
litwr, Do you want me to run the new tests with the stock A1200 68020 same as before, or using ACA-1232 68030 @ 33MHz (with 128mb fastram)? EDIT: Never mind, the ACA-1232 seems to be broken, so can't do 68030 for now. Amiga 1200 stock 68020 @ 14MHz with 4mb fastram Code:
pi-amiga-8 number ? calculator v8 [MULUopt](68000) number of digits (up to 9252)? 3000 314... 35.90 Code:
pi-amiga-8mo number ? calculator v8 [MULUopt](68000) number of digits (up to 9248)? 3000 314... 35.30 Code:
pi-amiga-9 number ? calculator v9(68000) number of digits (up to 9248)? 3000 314... 34.72 Code:
pi-amiga-9mo number ? calculator v9 [MULUopt](68000) number of digits (up to 9248)? 3000 314... 34.72 Code:
pi-amiga1200-8 number ? calculator v8 [MULUopt](68020) number of digits (up to 9252)? 3000 314... 36.72 Code:
pi-amiga1200-8mo number ? calculator v8 [MULUopt](68020) number of digits (up to 9248)? 3000 314... 35.54 Code:
pi-amiga1200-9 number ? calculator v9(68020) number of digits (up to 9252)? 3000 314... 35.00 Code:
pi-amiga1200-9mo number ? calculator v9 [MULUopt](68020) number of digits (up to 9248)? 3000 314... 34.94 EDIT 2: I played around with 'pi-amiga-9.asm' and modified it (edit/compile) to not print the digits via "Write(a6)" to stdout (under PR0000 label), just to see how much it would gain, and the result was 32.80 seconds, so that saved roughly 2 seconds. BTW: Noticed you have "jmp Write(a6)" on line 307 in 'pi-amiga-9.asm', shouldn't that be "jsr Write(a6)"? Last edited by modrobert; 02 May 2021 at 21:56. |
|
|
|
02 May 2021, 20:26
|
#27 | ||
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
BTW could you detach fast RAM and run PI-AMIGA-9MO for 3000 digits? Indeed it would also be nice to get results from your 68030 hardware sometime in the future. Quote:
The JMP instruction is ok - how could it work if it was wrong? 
|
||
|
|
|
02 May 2021, 21:19
|
#28 | ||
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
Quote:
Code:
pi-amiga-9mo number ? calculator v9 [MULUopt](68000) number of digits (up to 9248)? 9000 314... 291.88 Code:
pi-amiga1200-9mo number ? calculator v9 [MULUopt](68020) number of digits (up to 9248)? 9000 314... 294.38 Without fastram... Code:
pi-amiga-9mo number ? calculator v9 [MULUopt](68000) number of digits (up to 9248)? 3000 314... 36.84 Quote:
I noticed you don't select any type of RAM "clr.l d1" when allocating "AllocMem(a6)", according to documentation it should pick fastram first, but not sure if that can be overridden by compiler settings? |
||
|
|
|
02 May 2021, 21:45
|
#29 |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
litwr,
Check the attached screenshot regarding number of CPU cycles for DIVU.L. Source: https://www.nxp.com/docs/en/data-sheet/MC68020UM.pdf Last edited by BippyM; 01 June 2021 at 18:24. |
|
|
|
03 May 2021, 15:18
|
#30 | |
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
Code:
divu d4,d6
bvs.s .longdiv
moveq.l #0,d7
Code sequences at .longdiv are different but the branch to .longdiv is taken almost never, it is about 1 branch taken of 10,000,000 cases. I can only suggest one plausible explanation. Maybe your results are caused by programs run order. You ran PI-AMIGA-9 first. I can assume that this processing makes your hardware a bit hotter and slower. IMHO if you run PI-AMIGA1200-9MO first then it will be faster. If it is not right then I am completely baffled. Thank you for your remark about the AllocMem invocation. But I can't understand what compiler setting can affect memory allocation function call... |
|
|
|
|
03 May 2021, 15:20
|
#31 | |
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
|
|
|
|
|
03 May 2021, 15:42
|
#32 | |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
Quote:
Last edited by modrobert; 03 May 2021 at 15:52. |
|
|
|
|
03 May 2021, 15:53
|
#33 |
|
Registered User
Join Date: Jul 2015
Location: The Netherlands
Posts: 3,410
|
Regarding the timings of instructions, It should be pointed out that the timings in the Motorola manuals for the DIV and MUL instructions represent the maximum number of cycles they can take*, not the minimum. The actual timing varies depending on amongst other things the given input, though Motorola has not included information about how much this variation is**.
If I had to guess, I'd say that the 64 bit DIV instructions will probably perform worse than the 32 bit ones. *) From the manual linked above, page 8-11: "This CC time is a maximum since the times given for the MULU.L and DIVS.L are maximums.". **) See the introduction to chapter 8: "This section describes the instruction execution and operations (table searches, etc.) of the MC68020/EC020 in terms of external clock cycles. It provides accurate execution and operation timing guidelines but not exact timings for every possible circumstance. This approach is used since exact execution time for an instruction or operation is highly dependent on memory speeds and other variables." |

|
|
03 May 2021, 16:24
|
#34 | |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
Quote:
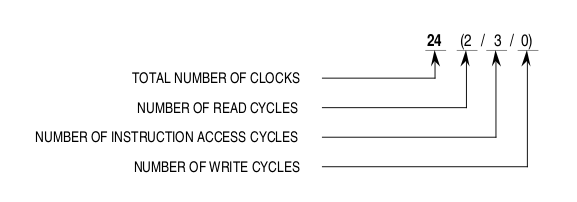 Time wise you can do roughly 20 ("average speed" ~4 clocks) instructions for the cost of one DIVU.L! Last edited by modrobert; 18 February 2024 at 17:10. |
|
|
|
|
03 May 2021, 16:42
|
#35 |
|
Registered User
Join Date: Jul 2015
Location: The Netherlands
Posts: 3,410
|
Best case through worst case in those diagrams only refer to time with instruction overlap/no overlap but in cache/no overlap not in cache*. They do not refer to the differences in timing for DIV/MUL due to different values or operand size being passed (in the case of the 64 bit operations).
*) The last one is especially interesting because it assumes memory access is penalized by just 1 cycle per access, which is way better than what the A1200 without Fast RAM actually manages. Edit: on a side note, it's very logical that DIV/MUL have different execution speeds based on differing inputs as the amount of work needed to be done for both does vary based on input. |
|
|
|
03 May 2021, 16:46
|
#36 |
|
old bearded fool
Join Date: Jan 2010
Location: Bangkok
Age: 56
Posts: 775
|
Here are the disassembled files attached for 'pi-amiga-9mo' and 'pi-amiga1200-9mo' binaries from 'pi-amiga-cmp.zip'. As you can see the 'pi-amiga1200-9mo' includes "divul.l d4,d7:d6", but this part of the code is not called much according to litwr. Lots of DIVU.W instructions in both which is slow as well.
Code:
lab_fa: divul.l d4,d7:d6 move.w d7,(a3) bra.b lab_12e Last edited by BippyM; 01 June 2021 at 18:24. |
|
|
|
03 May 2021, 17:26
|
#37 | |
|
Registered User
Join Date: Jan 2019
Location: Germany
Posts: 3,215
|
Quote:
Not really, they have the same amount of work to do. Your average division algorithm creates the remainder as by-product anyhow. The typical division implementation is a 2nbits/nbits division. IOWs, the underlying algorithm is probably much the same for all division versions, just that some of the outputs are thrown away and/or some of the inputs are assumed to be zero. |
|
|
|
|
03 May 2021, 17:41
|
#38 | |
|
Registered User
Join Date: Jan 2008
Location: Warsaw/Poland
Age: 55
Posts: 1,959
|
Quote:
245 times divu.w 1 time divu.l 387 times divu.w 1 time divu.l 1647 times divu.w 2 times divu.l etc up to f.e 10000 times if someone called this routine more than 10000 calls then old routine after 10000 times can be called within bvs check. |
|
|
|
|
03 May 2021, 17:50
|
#39 | ||
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
Have anybody ever tried to find those minimums? IMHO it is quite possible that minimum = maximum because some division implementations have constant time of executions for any their arguments.Quote:
I can again confirm that DIVUL is executed almost never.
|
||
|
|
|
03 May 2021, 17:52
|
#40 | |
|
Registered User
Join Date: Mar 2016
Location: Ozherele
Posts: 229
|
Quote:
|
|
|
|
| Currently Active Users Viewing This Thread: 1 (0 members and 1 guests) | |
| Thread Tools | |
 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| 68020 Bit Field Instructions | mcgeezer | Coders. Asm / Hardware | 9 | 27 October 2023 23:21 |
| 68060 64-bit integer math | BSzili | Coders. Asm / Hardware | 7 | 25 January 2021 21:18 |
| Discovery: Math | Audio Snow | request.Old Rare Games | 30 | 20 August 2018 12:17 |
| Math apps | mtb | support.Apps | 1 | 08 September 2002 18:59 |
|
|




