
|
 24 June 2024, 14:31
24 June 2024, 14:31
|
#81 | |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Quote:
So to use delta encoding, to increase the hit ratio ironically needs a table twice as large (to cover -256 to +255). |
|

|
|
24 June 2024, 16:33
|
#82 |
|
Registered User
Join Date: Feb 2017
Location: Denmark
Posts: 1,263
|
Result from updated code: 261131
clr.l is fine on 060, and I think 040 as well. Regarding scaling on 040, maybe there's a way to approximate it well enough with a (limited) number of shifts and adds. Just using the 2 most significant set bits in the scale seems to undershoot too much, but 3 looks decent, but maybe the numbers can be fudged a bit or something. |
|
|
|
24 June 2024, 17:08
|
#83 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Yeah, the jury is still out on the best way to do this for 040. Even so, I think a HQ setting may be ok, where it's just for the normalisation step. Like you said previously, it just makes it all "more interesting"...
|
|
|
|
24 June 2024, 22:16
|
#84 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Well I flummoxed myself just now.
I felt sure the delta issue was due to the range (-256 to +255) of the immediate difference of 2 8-bit values. Factoring everything in, this ended up just producing the same duff output as when I wasn't considering it. I say exact same, I didn't actually check at a binary levels, I just saw the same artefacts in the reconstituted wave. I am not seeing what the problem is. Suppose a and b are adjacent sample values and a is some amplification term, surely: a.c is the same as a.b + a(c - b), since expansion will cancel out a.b Or in more direct terms, amplification of delta values has the same net effect as amplifying linear values. |
|
|
|
24 June 2024, 22:20
|
#85 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
I refuse to be beaten by this. There has to be a "I'll kick myself when the penny drops" factor at play.
Perhaps the asymmetrical nature of 2's complement numbers, the fact that you can have -N to N-1 ot something. |
|
|
|
25 June 2024, 11:05
|
#86 |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,935
|
I'm not sure I understand the problem but my gut feeling tells me that I would have to check whether I am really taking the right samples from the sequence to receive the amplified audio from the delta encoded data. That sort of thing can easily result in some off-by-one error.
|
|
|
|
25 June 2024, 12:33
|
#87 | |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Quote:
Our scheme uses "frames" of audio that are always 16 samples (whether 8 or 16 bit) long and always cache aligned. We mix the next frame for up to 16 input channels, with separate left/right volumes into a pair of accumulation buffers (16-bit frame) that we then do the whole normalisation thing on. We mix a whole "packet", which is a number of frames, based on a provided mixing rate and desired update rate. So, for 16kHz with an update rate of 50Hz, we end up needing 320 samples, which is 20 frames. On the 68060 this is all done using arithmetic because multiplication is very fast. For 68040, we wish to avoid multiplication during mixing, since it takes ~18 cycles and in a worst case scenario, with 16 channels mixing we end up with 16 (channels) x 16 (frame length) x 2 (left / right volume) per frame, then another 32 more for normalisation. So we have an alternative approach (which was actually the original approach): 1. We have an input 8-bit sample stream for a virtual channel with a volume control. 2. Each 8-bit sample value is a lookup into a table of 16 bit values that are the product of the sample value, channel volume (and also the master mixer volume). 3. We directly look up each sample value and then add the resulting 16-bit value to the accumulaton buffer. 4. There are N-1 of these tables for each of the N volume levels (we don't have one for zero since that's a trivial case). 5. The tables are all cache aligned and sequentially arranged in memory. This all works just fine, but when you simulate how the tables are accessed as sets of 32 cache lines each, there is quite a spread. I simulated this with 500K of sample data, graphed below: 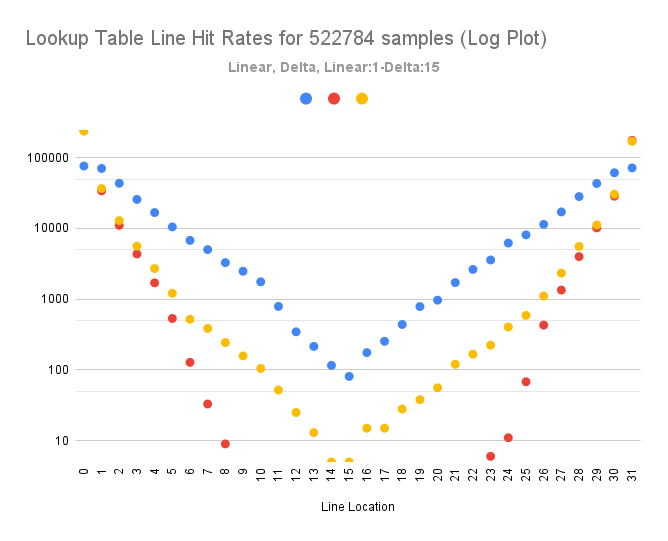 The blue plot shows the access pattern for a direct lookup. The 8-bit sample is just regarded as an unsigned 8-bit index into the table which is why it has the most accesses close to 0 and 255, since those are the small positive and negative values. If you consider there are up tio 16 channels to mix, each having a separate left/right volume level, we end up with a very scattered access to the table data and will be transferring a lot of cache lines. If you turn the 8-bit sample into a delta stream, unsurprisingly, the access to the table becomes dramatically more predictable, densely clustering around the small values. This is the red plot. For various reasons, it's better for us if we just do this delta one "frame" at a time, so we have a "linear-1, delta-15" variant that is a direct lookup of the first sample, followed by the delta values of the next 15. This is the yellow plot. It's almost as good as the red plot, when you consider the logarithmic vertical scale and still dramatically better than the blue one. These would result in only the first and last lines of each table being needed most of the time, which is a lot healthier for our small datacache. The assumption is that a fixed scaling factor (the volume) has the same effect on a delta value as it does a direct value. If you multiplied a delta stream by 10, on integration you'd get an output stream that was also multiplied by 10. Mathematically, this makes sense, anyway. Let's say our scaling factor is 1000 and we have the following 4 8-bit samples, and we lookup the first directly, but deltas of the following 3: 10, 5, 3, 6 Direct lookup would obviously give 10000, 5000, 3000, 6000 The proposed delta scheme gives: 10000, 1000(5 - 10), 1000(3-5), 1000(6-3) i.e. the values we looked up became 10, -5, 2, 3. Not radically closer together in this example but the yellow plot shows the real impact. Which obviously expands to: 10000, -5000, -2000, 3000 When reintegrated this is 10000, (10000 - 5000), (10000 - 5000 - 2000), (10000 - 5000 - 2000 + 3000) Which unsurprisingly is: 10000, 5000, 3000, 6000 Exactly the same as if we'd directly looked up each value. The difference being we looked up smaller values that were much closer together. However, in practise this isn't working. The values diverge pretty conspicuously. The first and most obvious thought I had was: "The range of possible outputs of the difference of 2 signed 8-bit numbers is a 9-bit value". So I changed the scheme to use 512-entry lookups that would be zero centred at index 256. I then used the actual sample lookup and delta as signed words (-256 to +255) to index the table for the corresponding amplified value. Related to this observation was the impact of modular arithmetic. You can delta encode 8 bit to 8 bit because of modulo-256 behaviour, but that doesn't mean you can just arbitrarily look up the result in a table because an 8-bit delta number could mean two things: is it -1 or is it +255 ? Even after this update It still went off, seemimgly in the same way. I haven't ruled out a bug in the logic but that's where we are up to. The saga continues.... |
|
|
|
|
25 June 2024, 12:47
|
#88 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
As for why I'm trying to do this, the simple fact is the datacache is the one feature of the 040 that I can leverage to make this as efficient as possible.
|
|
|
|
25 June 2024, 17:28
|
#89 | |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,935
|
Quote:
Btw, I'm impressed by your analysis. I wonder what the exp()-lookups required by my proposed low-spec approach would perform like when looking at cache efficiency. Assuming you have all audio data as log(sample), you would do the multiplication adding a constant value onto each value. In order to be able to sum the channels, you would need to perform the exp() lookup on each resulting value. My suspicion is that the lookups would be spread all over the table but something inside me screams µ-law and refuse to give up the idea... 
|
|
|
|
|
25 June 2024, 18:02
|
#90 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
I'm pretty sure it's a silly bug or a flaw in my reasoning.
As for uLaw, there may be scope for this in step 2: add a music stream. The current mixer silences the two left/right accumulation frames before mixing, but what it should do is to fill them with the next frames worth of 16-bit music from some source. A delta encoded uLaw type stream might be a good choice there. Especially one that can be done using easy shifts. You can encode the shift into the low bits, mask them off and shift the upper bits accordingly. |
|
|
|
25 June 2024, 18:32
|
#91 |
|
Registered User
Join Date: Feb 2017
Location: Denmark
Posts: 1,263
|
Looking at the 040 instruction timings, maybe it's actually faster to use the FPU? (I assume EC/LC versions are not as prevalent for 040 accelerator cards as they are now for 060).
And even if no-one with a working 040 steps up to the plate for testing, I guess we can get some decently useful timing information from my 060 with regards to cache performance and extrapolate from there. I can also see that there's a CACR bit to set the data cache in 1/2 mode, not sure if that means it's only using half (so same size as 040), but if it does, that should make things a bit easier. |
|
|
|
25 June 2024, 18:34
|
#92 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
I just wrote a quick and dirty script to validate that the underlying theory is ok. It successfully calculated every sample based on the delta scheme.
This is still subject to a lot of what-ifery, so I'll do a quick C conversion. It that works, the bug is in the implementation, not the concept. |
|
|
|
25 June 2024, 18:52
|
#93 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
I suspect the problem with an FPU implementation would be the cost of fmove on byte input and word output. You can get some degree of parallelism with the IU going though.
I was hoping to save the FPU for a possible improved precision geometry engine. Lol, as if that's going to be soon. |
|
|
|
25 June 2024, 19:10
|
#94 | |
|
Registered User
Join Date: Feb 2017
Location: Denmark
Posts: 1,263
|
Quote:
 But first, let's see how your delta stuff performs before getting ahead of ourselves, even if this stuff is exciting
|
|
|
|
|
25 June 2024, 19:19
|
#95 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
While we are on the subject of caches, I have to wonder how it might be if we could do the columnar wall rendering horizontally. Even if that meant rendering the image rotated and/or tiled. Every 1 pixel wide column to the row major framebuffer must be pretty horrible.
|
|
|
|
26 June 2024, 00:59
|
#96 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
I found a moment to port the test code to C to test with proper 8 and 16 bit types with all the truncation and modulo fun that comes with it. Anyway, it works.
The test script spits out the current values every 4096 samples processed in the same ~0.5MB dataset: Code:
Initialising table with scale factor 256 per level Loaded linear.raw [522784 bytes at 0x7b68ed859010] 0: -6 => -1536 [A -1536 => -1536] [B -1536 => -1536] 4096: 6 => 1536 [A -256 => 1536] [B -256 => 1536] 8192: -14 => -3584 [A -768 => -3584] [B -768 => -3584] 12288: -18 => -4608 [A 512 => -4608] [B 512 => -4608] 16384: 22 => 5632 [A -5632 => 5632] [B -5632 => 5632] 20480: -67 => -17152 [A -256 => -17152] [B -256 => -17152] 24576: -44 => -11264 [A -256 => -11264] [B -256 => -11264] 28672: -1 => -256 [A 2816 => -256] [B 2816 => -256] 32768: -20 => -5120 [A -768 => -5120] [B -768 => -5120] 36864: -31 => -7936 [A -256 => -7936] [B -256 => -7936] 40960: 8 => 2048 [A -256 => 2048] [B -256 => 2048] 45056: -14 => -3584 [A 2048 => -3584] [B 2048 => -3584] 49152: -10 => -2560 [A -1024 => -2560] [B -1024 => -2560] 53248: 4 => 1024 [A 0 => 1024] [B 0 => 1024] 57344: 8 => 2048 [A -512 => 2048] [B -512 => 2048] 61440: 23 => 5888 [A 1792 => 5888] [B 1792 => 5888] 65536: 74 => 18944 [A 3584 => 18944] [B 3584 => 18944] 69632: -20 => -5120 [A 2560 => -5120] [B 2560 => -5120] 73728: 17 => 4352 [A -768 => 4352] [B -768 => 4352] 77824: 12 => 3072 [A 0 => 3072] [B 0 => 3072] 81920: -21 => -5376 [A 0 => -5376] [B 0 => -5376] 86016: 4 => 1024 [A -512 => 1024] [B -512 => 1024] 90112: 10 => 2560 [A 0 => 2560] [B 0 => 2560] 94208: 8 => 2048 [A 256 => 2048] [B 256 => 2048] 98304: 1 => 256 [A 256 => 256] [B 256 => 256] 102400: 0 => 0 [A 256 => 0] [B 256 => 0] 106496: 18 => 4608 [A -768 => 4608] [B -768 => 4608] 110592: -18 => -4608 [A 512 => -4608] [B 512 => -4608] 114688: 11 => 2816 [A 768 => 2816] [B 768 => 2816] 118784: 45 => 11520 [A 2816 => 11520] [B 2816 => 11520] 122880: 4 => 1024 [A -6912 => 1024] [B -6912 => 1024] 126976: -12 => -3072 [A 0 => -3072] [B 0 => -3072] 131072: 9 => 2304 [A 2048 => 2304] [B 2048 => 2304] 135168: -11 => -2816 [A -512 => -2816] [B -512 => -2816] 139264: -9 => -2304 [A 1536 => -2304] [B 1536 => -2304] 143360: -37 => -9472 [A -1024 => -9472] [B -1024 => -9472] 147456: -29 => -7424 [A 512 => -7424] [B 512 => -7424] 151552: 13 => 3328 [A 1280 => 3328] [B 1280 => 3328] 155648: -24 => -6144 [A 0 => -6144] [B 0 => -6144] 159744: -82 => -20992 [A 5120 => -20992] [B 5120 => -20992] 163840: -8 => -2048 [A -512 => -2048] [B -512 => -2048] 167936: 7 => 1792 [A 1792 => 1792] [B 1792 => 1792] 172032: -21 => -5376 [A 1280 => -5376] [B 1280 => -5376] 176128: -27 => -6912 [A 2304 => -6912] [B 2304 => -6912] 180224: 10 => 2560 [A 256 => 2560] [B 256 => 2560] 184320: 11 => 2816 [A -512 => 2816] [B -512 => 2816] 188416: 16 => 4096 [A 2304 => 4096] [B 2304 => 4096] 192512: -51 => -13056 [A 768 => -13056] [B 768 => -13056] 196608: 64 => 16384 [A -7424 => 16384] [B -7424 => 16384] 200704: -53 => -13568 [A 0 => -13568] [B 0 => -13568] 204800: 14 => 3584 [A -512 => 3584] [B -512 => 3584] 208896: -5 => -1280 [A -256 => -1280] [B -256 => -1280] 212992: 13 => 3328 [A -5632 => 3328] [B -5632 => 3328] 217088: 0 => 0 [A 0 => 0] [B 0 => 0] 221184: -14 => -3584 [A 768 => -3584] [B 768 => -3584] 225280: 2 => 512 [A 0 => 512] [B 0 => 512] 229376: 15 => 3840 [A -512 => 3840] [B -512 => 3840] 233472: 1 => 256 [A -3328 => 256] [B -3328 => 256] 237568: 16 => 4096 [A 0 => 4096] [B 0 => 4096] 241664: -18 => -4608 [A -256 => -4608] [B -256 => -4608] 245760: 50 => 12800 [A -2048 => 12800] [B -2048 => 12800] 249856: -11 => -2816 [A -256 => -2816] [B -256 => -2816] 253952: 12 => 3072 [A 0 => 3072] [B 0 => 3072] 258048: 3 => 768 [A 768 => 768] [B 768 => 768] 262144: -9 => -2304 [A -1024 => -2304] [B -1024 => -2304] 266240: 12 => 3072 [A 512 => 3072] [B 512 => 3072] 270336: -10 => -2560 [A -1024 => -2560] [B -1024 => -2560] 274432: 5 => 1280 [A 256 => 1280] [B 256 => 1280] 278528: -37 => -9472 [A 256 => -9472] [B 256 => -9472] 282624: 35 => 8960 [A -9728 => 8960] [B -9728 => 8960] 286720: -43 => -11008 [A -1024 => -11008] [B -1024 => -11008] 290816: -12 => -3072 [A 0 => -3072] [B 0 => -3072] 294912: -6 => -1536 [A -512 => -1536] [B -512 => -1536] 299008: -4 => -1024 [A 2304 => -1024] [B 2304 => -1024] 303104: 10 => 2560 [A -1024 => 2560] [B -1024 => 2560] 307200: -3 => -768 [A 0 => -768] [B 0 => -768] 311296: 2 => 512 [A 512 => 512] [B 512 => 512] 315392: 36 => 9216 [A -512 => 9216] [B -512 => 9216] 319488: -55 => -14080 [A 3584 => -14080] [B 3584 => -14080] 323584: 6 => 1536 [A -2560 => 1536] [B -2560 => 1536] 327680: -43 => -11008 [A 0 => -11008] [B 0 => -11008] 331776: -40 => -10240 [A -6400 => -10240] [B -6400 => -10240] 335872: -8 => -2048 [A -2048 => -2048] [B -2048 => -2048] 339968: -23 => -5888 [A 0 => -5888] [B 0 => -5888] 344064: 5 => 1280 [A 0 => 1280] [B 0 => 1280] 348160: -28 => -7168 [A 0 => -7168] [B 0 => -7168] 352256: 12 => 3072 [A 4864 => 3072] [B 4864 => 3072] 356352: 67 => 17152 [A -1024 => 17152] [B -1024 => 17152] 360448: -45 => -11520 [A -1024 => -11520] [B -1024 => -11520] 364544: -41 => -10496 [A 0 => -10496] [B 0 => -10496] 368640: 0 => 0 [A 3072 => 0] [B 3072 => 0] 372736: -56 => -14336 [A 3072 => -14336] [B 3072 => -14336] 376832: 10 => 2560 [A 2560 => 2560] [B 2560 => 2560] 380928: 3 => 768 [A 256 => 768] [B 256 => 768] 385024: 3 => 768 [A 1024 => 768] [B 1024 => 768] 389120: -18 => -4608 [A 0 => -4608] [B 0 => -4608] 393216: -7 => -1792 [A -512 => -1792] [B -512 => -1792] 397312: 3 => 768 [A 768 => 768] [B 768 => 768] 401408: 4 => 1024 [A -512 => 1024] [B -512 => 1024] 405504: 12 => 3072 [A 256 => 3072] [B 256 => 3072] 409600: -47 => -12032 [A -768 => -12032] [B -768 => -12032] 413696: -30 => -7680 [A -3072 => -7680] [B -3072 => -7680] 417792: 7 => 1792 [A -768 => 1792] [B -768 => 1792] 421888: -14 => -3584 [A 1280 => -3584] [B 1280 => -3584] 425984: -18 => -4608 [A -1536 => -4608] [B -1536 => -4608] 430080: 11 => 2816 [A 6656 => 2816] [B 6656 => 2816] 434176: 19 => 4864 [A 0 => 4864] [B 0 => 4864] 438272: 14 => 3584 [A 1792 => 3584] [B 1792 => 3584] 442368: 82 => 20992 [A 2304 => 20992] [B 2304 => 20992] 446464: -11 => -2816 [A 512 => -2816] [B 512 => -2816] 450560: -15 => -3840 [A 2048 => -3840] [B 2048 => -3840] 454656: 15 => 3840 [A 512 => 3840] [B 512 => 3840] 458752: -1 => -256 [A 2048 => -256] [B 2048 => -256] 462848: 10 => 2560 [A -256 => 2560] [B -256 => 2560] 466944: 25 => 6400 [A -2560 => 6400] [B -2560 => 6400] 471040: 14 => 3584 [A -256 => 3584] [B -256 => 3584] 475136: 7 => 1792 [A 1280 => 1792] [B 1280 => 1792] 479232: -5 => -1280 [A 256 => -1280] [B 256 => -1280] 483328: 76 => 19456 [A -1024 => 19456] [B -1024 => 19456] 487424: -34 => -8704 [A -3072 => -8704] [B -3072 => -8704] 491520: -28 => -7168 [A -256 => -7168] [B -256 => -7168] 495616: -15 => -3840 [A -2048 => -3840] [B -2048 => -3840] 499712: -63 => -16128 [A 2304 => -16128] [B 2304 => -16128] 503808: -20 => -5120 [A -256 => -5120] [B -256 => -5120] 507904: 7 => 1792 [A 0 => 1792] [B 0 => 1792] 512000: -14 => -3584 [A 256 => -3584] [B 256 => -3584] 516096: -23 => -5888 [A 0 => -5888] [B 0 => -5888] 520192: -5 => -1280 [A 0 => -1280] [B 0 => -1280] Tested 522784 samples. Min/Max delta_8 -69/68 The block labelled B is the proposed delta path where we look up the 8-bit delta and integrate it. As you can see, it works fine all the way through and moreover, the peak 8 (technically 9) bit delta were literally nowhere near the -256/+255 limits. To hit those, you'd have to have have an extreme input signal with peak to peak transitions. That just doesn't happen in normal audio. So, based on that, it might be fine to keep the tables 256 entry and just put a redzone around the first and last table for out of bounds reads. In the very worst case, you'd get a glitched single frame. |
|
|
|
26 June 2024, 01:15
|
#97 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
The obvious conclusion is that the idea is fine and I just can't code.
[ Show youtube player ] |
|
|
|
29 June 2024, 19:45
|
#98 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Finally a quiet moment to take another stab at it. I don't know what I did wrong before but I reverted all the commits to see if I make the same mistake again now that I know the concept itself has been validated...
|
|
|
|
29 June 2024, 19:56
|
#99 |
|
Alien Bleed
Join Date: Aug 2022
Location: UK
Posts: 4,667
|
Lol, spoke too soon.
|
|
|
|
29 June 2024, 22:20
|
#100 | |
|
Registered User
Join Date: Oct 2020
Location: Bicester
Posts: 2,056
|
Quote:

|
|
|
|
| Currently Active Users Viewing This Thread: 2 (0 members and 2 guests) | |
| Thread Tools | |
 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| Slow A4000 after overhaul | Screechstar | support.Hardware | 57 | 11 July 2023 23:02 |
| Amiga Font Editor overhaul | buggs | Coders. Releases | 19 | 09 March 2021 17:39 |
| Escom A1200 overhaul | Ox. | Amiga scene | 8 | 26 August 2014 08:54 |
| Will Bridge Practice series needs an overhaul | mk1 | HOL data problems | 1 | 02 April 2009 21:55 |
|
|




