
|
 27 November 2019, 20:20
27 November 2019, 20:20
|
#81 | |
|
It's coming back!
Join Date: Jul 2018
Location: comp.sys.amiga
Posts: 762
|
Quote:
You always have a constant bit. Then a bit that grows with the number of objects you draw, or whatever. It's the second bit that's important. Ideally you also get a growth that doesn't become exponential, and stuff that's outside this conversation. But to measure improvement you have to remove that constant bit. |
|

|
|
27 November 2019, 20:21
|
#82 |
|
Registered User
Join Date: Jun 2016
Location: europe
Posts: 1,039
|
To go back to the original discussion...
One way of speeding it up further would probably be to switch loop order (1..100 outer and 1..3 inner is slower than 1..3 outer and 1..100 inner), since there are 3 nested loops and the inner 2 have small repetition count. Also, I usually hardcode the depth (=> unrolling), which should be totally reasonable for a game/demo, and that would free another register and eliminate swaps. |
|
|
|
27 November 2019, 20:26
|
#83 | |
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
@deimos:
Okay, now i understand, what you wanted: we're back at the start again and you're saying the direct approach is better for measurements and measuring the change in time by measuring the whole runtime and comparing it between two versions is flawed and will not show the true performance gain. And again you do without actual countermeasures. You may be right, but during the time you stated this for the umpteenth time, you could change the code and measure it by the direct way. But now i am really curious, what would do such an impact on the precision, if it is measured by comparing total running times? Quote:
@a/b: This is a three loop copy. We could unroll the depth by cloning the routine for each depth from 1 to 8, but how would you unroll the innermost loop? I've tried your trick with the other routine, that i unroll it for 8 and do the rest, but it did not get faster. Or did you mean something else? Last edited by TCH; 27 November 2019 at 20:36. Reason: a/b arrived in the meantime, doublepost from deimos |
|
|
|
|
27 November 2019, 20:43
|
#84 | |||
|
It's coming back!
Join Date: Jul 2018
Location: comp.sys.amiga
Posts: 762
|
Quote:
Quote:
Quote:
|
|||
|
|
|
27 November 2019, 21:14
|
#85 | ||||
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
Quote:
Quote:
Quote:
Quote:
Last edited by TCH; 27 November 2019 at 21:16. Reason: typo |
||||
|
|
|
27 November 2019, 21:36
|
#86 | ||||
|
It's coming back!
Join Date: Jul 2018
Location: comp.sys.amiga
Posts: 762
|
Quote:
Quote:
Quote:
Quote:
I did try to help. Really. |
||||
|
|
|
27 November 2019, 21:44
|
#87 | |
|
ex. demoscener "Bigmama"
Join Date: Jun 2012
Location: Fyn / Denmark
Posts: 1,624
|
Quote:
 Now we just need it to generate motorola syntax 
|
|
|
|
|
27 November 2019, 22:11
|
#88 | ||||||
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
Quote:
Quote:
Quote:
Quote:
vasmm68k_mot ClearBlock32.68k -spaces -Fhunk -o ClearBlock32.o && vasmm68k_mot PolygonBitmapToPlanes32.3.68k -spaces -Fhunk -o PolygonBitmapToPlanes32.3.o) and then compile the C file together with the object files ( m68k-amigaos-gcc -O2 polygon1.c *.o -o polygon1). It is true, that i did not said this explicitly, but i thought this was trivial. As for the 'amtime', i've released it in this topic a few days ago. It was also on coders general, so i thought you've seen it, but i admit, this was not trivial, so i apologize for this mistake. Quote:
Quote:
So, i tried to cooperate. Really. |
||||||
|
|
|
27 November 2019, 22:47
|
#89 | |
|
It's coming back!
Join Date: Jul 2018
Location: comp.sys.amiga
Posts: 762
|
Quote:
|
|
|
|
|
27 November 2019, 23:02
|
#90 |
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
Of course i don't type this by hand all the time, i have a small buildscript. (With some additional parts, for switching OS or CPU and other stuff, but those parts are irrelevant here.)
But based on your comments, you use windows, so a POSIX shellscript would be useless for you and i have no idea how would i had to do these calls and any related stuff under windows, so i could not provided you a batchfile. As for providing a makefile, i also have no idea if a UNIX makefile even works under windows or not. It's just that, it's just three line for putting together the C with the two assembly file and i thought you can write your own batch or makefile. |
|
|
|
27 November 2019, 23:26
|
#91 | |
|
OCS forever!
Join Date: Mar 2019
Location: Birmingham, UK
Posts: 418
|
Quote:
|
|
|
|
|
28 November 2019, 10:53
|
#92 |
|
Registered User
Join Date: Jul 2015
Location: The Netherlands
Posts: 3,421
|
About the time measuring... Measuring the total execution time of the program rather than just the part of the code that you've changed will obviously report a lower percentage improvement than measuring just the code that changed. After all, you're adding in (effectively) static overhead for each run.
This may be a valid way to measure overall program performance (which may indeed be what you want to know), but won't measure the performance gain of the new code itself fairly. However, this can be mostly fixed - simply make sure that the part you wish to know about (the fill in this case) takes up a fairly large chunk of time. Rather than having the code & program running a few seconds, have it run a minute (or perhaps even more if it's a large or floppy disk based program) or so. The goal is to effectively make any overhead of the OS/init trivial in comparison to the code you want to test. This should give a fairly accurate result. Perhaps this is a possibly better approach if you don't want to measure the run time inside of the program itself? |
|
|
|
28 November 2019, 15:49
|
#93 |
|
Registered User
Join Date: Jun 2016
Location: europe
Posts: 1,039
|
New try: using d/y/x loops instead of y/d/x.
Modulo must be calculated *differently*!!. Instead of (bitmap_width*bitmap_height-blit_width)>>2 you have to pass this in d2 (bitmap_width*(bitmap_height-blit_height))>>2 Code:
movem.l d2-d7/a2-a6,-(a7) asl.l #2,d2 ; longwords to bytes move.w d1,d7 asl.w #2,d7 ; longwords to bytes sub.w d7,d3 move.w d3,a6 ; a6 = Rowsize-Width<<2; subq.w #1,d0 ; Height--; subq.w #1,d1 ; Width--; subq.w #1,d4 ; Depth--; move.w d0,a5 c_p: move.l 8<<2(a2),a4 ; NextPattern move.l a1,a3 ; SrcPtr = TempArea; move.l (a2)+,d6 ; CurrentPattern move.w a5,d3 ; HeightCounter c_h: move.w d1,d5 ; WidthCounter c_w: move.l (a0),d7 move.l d6,d0 eor.l d7,d0 and.l (a3)+,d0 eor.l d7,d0 move.l d0,(a0)+ ; *DestPtr++ = (*DestPtr&~Temp)|(CurrentPattern&Temp); dbf d5,c_w ; if (--WidthCounter >= 0) goto c_w; adda.l a6,a0 ; DestPtr += RowSize-Width<<2; adda.l a6,a3 ; SrcPtr += RowSize-Width<<2; exg d6,a4 ; swap patterns dbf d3,c_h ; if (--HeightCounter >= 0) goto c_h; adda.l d2,a0 ; DestPtr += Modulo<<2; dbf d4,c_p ; if (--Depth >= 0) goto c_p; movem.l (a7)+,d2-d7/a2-a6 rts |
|
|
|
28 November 2019, 20:27
|
#94 |
|
Registered User
Join Date: Jun 2016
Location: europe
Posts: 1,039
|
Getting annoyed? Good, there is more ;P.
Code:
movem.l d2-d7/a2-a6,-(a7) asl.l #2,d2 ; longwords to bytes move.w d1,d7 asl.w #2,d7 ; longwords to bytes sub.w d7,d3 move.w d3,a6 ; a6 = Rowsize-Width<<2; subq.w #1,d0 ; Height--; subq.w #1,d1 ; Width--; subq.w #1,d4 ; Depth--; move.w d0,a5 move.w d1,a4 c_p: move.l 8<<2(a2),d1 ; NextPattern move.l a1,a3 ; SrcPtr = TempArea; move.l (a2)+,d6 ; CurrentPattern move.w a5,d3 ; HeightCounter lsr.w #1,d3 bcc.s odd_h c_h: move.w a4,d5 ; WidthCounter c_w1: move.l (a0),d7 move.l d6,d0 eor.l d7,d0 and.l (a3)+,d0 eor.l d7,d0 move.l d0,(a0)+ ; *DestPtr++ = (*DestPtr&~Temp)|(CurrentPattern&Temp); dbf d5,c_w1 ; if (--WidthCounter >= 0) goto c_w; adda.l a6,a0 ; DestPtr += RowSize-Width<<2; adda.l a6,a3 ; SrcPtr += RowSize-Width<<2; odd_h: move.w a4,d5 ; WidthCounter c_w2: move.l (a0),d7 move.l d1,d0 eor.l d7,d0 and.l (a3)+,d0 eor.l d7,d0 move.l d0,(a0)+ ; *DestPtr++ = (*DestPtr&~Temp)|(CurrentPattern&Temp); dbf d5,c_w2 ; if (--WidthCounter >= 0) goto c_w; adda.l a6,a0 ; DestPtr += RowSize-Width<<2; adda.l a6,a3 ; SrcPtr += RowSize-Width<<2; dbf d3,c_h ; if (--HeightCounter >= 0) goto c_h; adda.l d2,a0 ; DestPtr += Modulo<<2; dbf d4,c_p ; if (--Depth >= 0) goto c_p; movem.l (a7)+,d2-d7/a2-a6 rts |
|
|
|
30 November 2019, 00:23
|
#95 | |
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
@roondar:
The problem with this overhead what the OS gives, that it exists in both measures and it's always almost the same, so there should not be any big difference. But, okay, i gave in. In a neighbouring topic i just released two timer units, here is the internal measuring by public demand. First however, i measured the difference with the external tool. I've run the program ten times in both cases. Here is the times of the C algorithm: 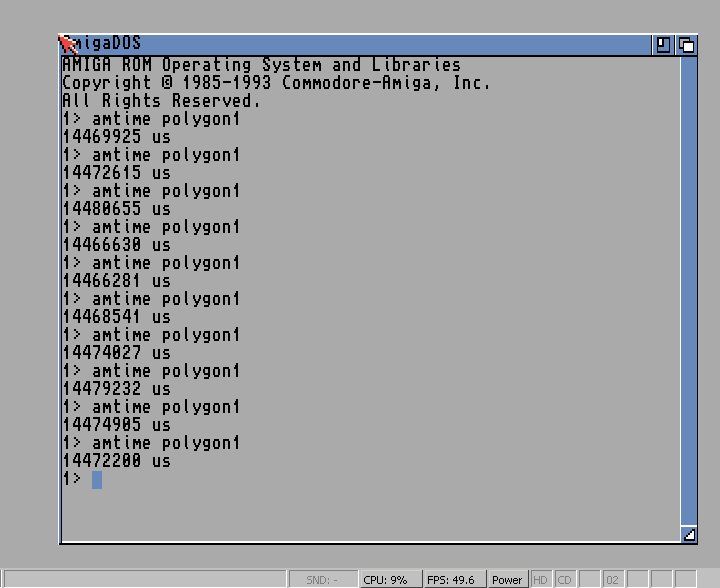 And here is the ASM (not this newest two a/b provided yesterday, the one before them):  Calculating an average from the times and then calculating the difference gives a 3.7466% as the result. Now, deimos claimed: Quote:
Here are the internally measured runs (modified C file here: http://oscomp.hu/depot/polygon1.c):  After calculating the averages, the difference here is 5.3153%. Which means - if we assume, that this is really the more accurate measuring - that the assembly routine were actually 1.5687% faster than the external measures has shown. This is nowhere from the 5 and 10 times bigger numbers deimos predicted. This entire discussion about the measuring was a big waste of time... @a/b: Nope, i am not annoyed, i am always grateful any help, thank you. However this version crashed. Did i understood correctly that Moduloshould be (320*(256-h))>>2? |
|
|
|
|
30 November 2019, 00:41
|
#96 |
|
Registered User
Join Date: Jun 2016
Location: europe
Posts: 1,039
|
Oh, crap... My bad, it's supposed to be /32 (or (/8)>>2), which is pixels to longwords. I have it written correctly in my test code, but I only copy/pasted the actual function.
Old/new modulo, blit is 256x128px: Code:
; move.l #Width*Height/32-256/32,d2 move.l #Width*(Height-Height/2)/32,d2 |
|
|
|
30 November 2019, 00:59
|
#97 |
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
Got it, now works. And wow, 4% gain, now the assembly routine is almost 10% faster than the C one.
Yeah, i hear you. Quite interesting though, that originally the planes were the outer cycle, but as i said in the opening post, it was 2x slower. I really have to analyse this code, but time is scarce here too... Anyways, thanks again. |
|
|
|
30 November 2019, 15:45
|
#98 | ||||
|
Registered User
Join Date: Jul 2015
Location: The Netherlands
Posts: 3,421
|
Quote:
Quote:
It all boils down to perspective - you're looking purely at the level of improvement over the original code. In that case, 5.3% vs 3.7% isn't a big deal and you're correct in pointing that out. I was looking at how accurate the measurement was for seeing the improvement in the algorithm you changed, in which case reporting 5.3% instead of 3.7% is actually a pretty big 'error'. Quote:
I thought the difference of opinion was not about what was more accurate but rather whether the 'amtime' option was 'good enough'. Personally, I think your example showed it wasn't really. But your mileage might vary and I respect your opinion in the matter. I was only trying to offer an alternative, not start an argument. Quote:
|
||||
|
|
|
30 November 2019, 17:16
|
#99 | ||
|
Newbie Amiga programmer
Join Date: Jun 2012
Location: Front of my A500+
Age: 38
Posts: 372
|
Quote:
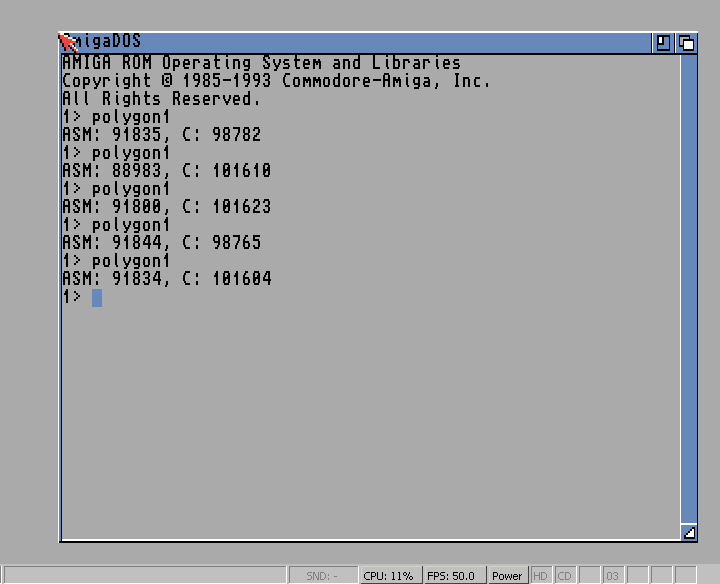 It shows ~3-~3% differences for the very same routines. With the external measure, the difference between runs was under 0.1%. Quote:
Last edited by TCH; 30 November 2019 at 20:29. Reason: missing 'is' |
||
|
|
|
30 November 2019, 22:12
|
#100 | ||
|
Registered User
Join Date: Jul 2015
Location: The Netherlands
Posts: 3,421
|
Quote:
This discussion is getting fairly far off topic, I think everyone has said what we want on the issue and if not: I suggest we either discuss the pro's and con's of internal/external timing in the thread you made for the timing unit you wrote or make a separate thread about. Quote:
Anyway, back to seeing if better code can be figured out yet 
|
||
|
|
| Currently Active Users Viewing This Thread: 1 (0 members and 1 guests) | |
| Thread Tools | |
 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| Optimizing HAM8 renderer. | Thorham | Coders. Asm / Hardware | 5 | 22 June 2017 18:29 |
| NetSurf AGA optimizing | arti | Coders. Asm / Hardware | 199 | 10 November 2013 14:36 |
| Layered tile engine optimizing. | Thorham | Coders. General | 0 | 30 September 2011 20:43 |
| Benching and optimizing CF-IDE speed | Photon | support.Hardware | 12 | 15 July 2009 01:48 |
| For people who like optimizing 680x0 code. | Thorham | Coders. General | 5 | 28 May 2008 11:48 |
|
|




