
|
 30 October 2016, 09:00
30 October 2016, 09:00
|
#1 |
|
Apollo Team
Join Date: May 2014
Location: not far
Posts: 379
|
RiVa AMMX Benchmarks
Since start of the Apollo 68080 adventure, Stephen Fellner, author of the RiVa MPEG Player, was kind enough to share sources of his player with the Apollo team.
As some of you might have followed the changes in core over the last months, AMMX instructions were introduced in the Apollo-Core, meaning that software that take benefit from them experience big speedups. With the dedicated work of buggs and flype, RiVa has been modified to take advantages from those AMMX instructions. Here are some results :  Core: Apollo 68080 AMMX Core, Revision 3543, x11 speed RiVa Parameters : VERBOSE NOAUDIO DISPLAY=HICOLOR NOSKIP FPS=1000 Download links : Original RiVa TopGun 320 Video TopGun 640 Video IQ has also been greatly improved (YUYV versus R5G6B5 quality) and stereo audio has also been enabled ! All this is still WIP and should be part of next GOLD2 release  Stay tuned ! 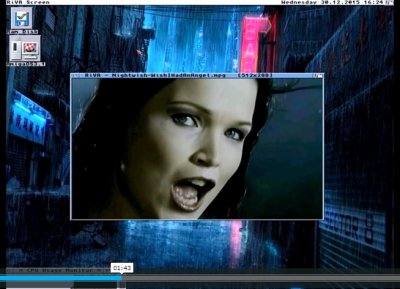
Last edited by TuKo; 30 October 2016 at 10:46. |

|
|
30 October 2016, 14:21
|
#2 |
|
Registered User
Join Date: Sep 2016
Location: UK
Posts: 10
|
This is very awesome!

|
|
|
|
31 October 2016, 08:39
|
#3 |
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
This is just empty talk without showing the actual code (both before and after).
I can get +200% and more by just rewriting compiled code into ASM, no need for AMMX. |
|
|
|
31 October 2016, 09:15
|
#4 |
|
Registered User
Join Date: Aug 2007
Location: berlin/germany
Posts: 1,054
|
I think it would be great if you joined in and contributed to make riva faster also for regular amigas.
|
|
|
|
31 October 2016, 09:15
|
#5 | |
|
Apollo Team
Join Date: May 2014
Location: not far
Posts: 379
|
Quote:
Thanks for your encouraging message ! We would be very happy to have your skills in team to continue the improvement. Would you like to join ? P.S. : RiVa is already 100% ASM. |
|
|
|
|
31 October 2016, 09:26
|
#6 | |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,918
|
Quote:
|
|
|
|
|
31 October 2016, 09:32
|
#7 | ||||
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Quote:
Quote:
Quote:
Quote:
|
||||
|
|
|
31 October 2016, 11:22
|
#8 |
|
Apollo Team
Join Date: May 2014
Location: not far
Posts: 379
|
Here is a screenshot of improvement on 68060 (A4000 with CS060MK-I and Cybervision 64) :
 Original 0.50 on top, new at bottom That's a 17.85% improvement. Looking forward for 200%. Last edited by TuKo; 31 October 2016 at 11:44. |
|
|
|
31 October 2016, 16:32
|
#9 | |
|
Registered User
Join Date: Dec 2014
Location: France
Posts: 104
|
Quote:
I agree. It seems little large for. But it is. I can confim you it is 100% ASM, not a single line in C - even for reading the tooltypes and command line arguments :-) It use the MPEGA.library for decoding the audio (which is also written in ASM). The full chain is ASM afaik. The original source code, kindly shared by S. Fellner himself, is about 400KB of pure ASM (and some tables), and main file is about 15 000 lines, which is quite equivalent to the MPEGA itself. Legacy code is already impressive and optimized ; it has been preserved even for the Apollo project and some improvements have been added in code. The work done by Buggs is a very serious one, respectful to the legacy code and brings new AMMX dedicated code but not only (68060 benefits also from the recent work). Maintaining RiVA is a serious project which needs serious 68k skills - we speak in it of all the 68k features panel, superscalar, inst/data caches, cache hits, branch predicts, accuracy of decoding, accuracy of rendering, accuracy of testings, ... Other facts, the RiVA project compiles on my V600 in less than 8 seconds using last VASM_mot for 68000... and 68080 support. This is very acceptable compile time against a gcc project, by far. Of course 100% ASM is hardly maintainable and requires some weeks to understands. Last edited by flype; 01 November 2016 at 01:50. |
|
|
|
|
31 October 2016, 17:51
|
#10 |
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Yeah maybe, but mpega.library isn't 100% asm to start with (only critical parts were initially asm ; i got significant speedup by rewriting the huffman decoding). It's around 250-300k source (from resourced), without tables. It was compiled with SAS/C in 020+ mode (yeah i can see that when disassembling, heheh).
If RiVa isn't much bigger than mpega then it's perfectly manageable. Now i'm wondering if old MPEG-1 is still worth the trouble, with all these MPEG-4 videos all around... I don't believe in mmx and related stuff, and will not until i see normal handwritten asm beaten by a large amount, counting individual clocks in the routine(s). This is why  i want to see the code i want to see the code (i have the slight impression that i will have to repeat my last sentence a few times...) |
|
|
|
31 October 2016, 19:34
|
#11 |
|
Registered User
Join Date: May 2016
Location: Rostock/Germany
Posts: 132
|
Well Meynaf, you'd like to see some code? Here you go. Core loop inhorizontal interpolation as an example. Hope, the post ain't too long.
Original (core loop over two pixels, without proper rounding): Code:
.y_xloop move.b (a1)+,d2 ;d2: --- --- --- 1
add.l d2,d1 ;d1: --- --- --- 0+1
lsr.l #1,d1 ;d1: --- --- --- 0\1
move.b d1,(a2)+
move.b (a1)+,d1 ;d1: --- --- --- 2
add.l d1,d2 ;d2: --- --- --- 1+2
lsr.l #1,d2 ;d2: --- --- --- 1\2
move.b d2,(a2)+
dbf d6,.y_xloop
Code:
move.l (a1),d1 ; P00 P01 P02 P03
move.l 1(a1),d2 ; P01 P02 P03 P04
move.l d1,d3
or.l d2,d3 ; P00|P01 P01|P02 P02|P03 P03|P04 -> meaning: we need to add "1" whenever any of the operands has it's LSB set
and.l d6,d1 ; upper 7 bits P00 P01 P02 P03
and.l d6,d2 ; upper 7 bits P01 P02 P03 P04
lsr.l #1,d1 ;
lsr.l #1,d2 ;
and.l d0,d3 ; keep the 1
add.l d1,d2 ; P00+P01 .. .. ..
move.l 4(a1),d1 ; P04 P05 P06 P07
add.l d3,d2 ; (P00+P01+1)>>1 .. .. ..
move.l 5(a1),d7 ; P05 P06 P07 P08
move.l d2,(a2)+
move.l d1,d3
or.l d7,d3 ; P00|P01 P01|P02 P02|P03 P03|P04 -> meaning: we need to add "1" whenever any of the operands has it's LSB set
and.l d6,d1 ; upper 7 bits P00 P01 P02 P03
and.l d6,d7 ; upper 7 bits P01 P02 P03 P04
lsr.l #1,d1 ;
lsr.l #1,d7 ;
and.l d0,d3 ; keep the 1
add.l d1,d7 ; P00+P01 .. .. ..
add.l d3,d7 ; (P00+P01+1)>>1 .. .. ..
move.l d7,(a2)+
Code:
LOADAB 1,0 ; LOAD (A1),B0
PAVGd16ABB 1,1,0,1 ; PAVG.B 1(A1),B0,B1
STOREApB 2,1 ; STORE B1,(A2)+
Last edited by buggs; 31 October 2016 at 19:44. Reason: restored the "+" in the last code statement, got lost in c+p |
|
|
|
31 October 2016, 20:25
|
#12 | |
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Quote:
This is horizontal interpolation (from jpeg decoder) - try to rewrite it with SIMD if you wish : Code:
; a0 = input, a1 = output ; 1st row moveq #0,d1 moveq #0,d0 move.b (a0)+,d1 move.b (a0)+,d0 move.b d1,(a1)+ move.l d1,d2 add.l d2,d2 add.l d1,d2 add.l d0,d2 addq.l #2,d2 lsr.l #2,d2 move.b d2,(a1)+ ; general case moveq #0,d2 .xloop move.l d0,d3 add.l d3,d3 add.l d0,d3 add.l d3,d1 addq.l #1,d1 lsl.l #6,d1 move.b (a0)+,d2 add.l d2,d3 addq.l #2,d3 lsr.l #2,d3 move.b d3,d1 move.w d1,(a1)+ move.l d0,d1 move.l d2,d0 dbf d6,.xloop ; last row move.l d0,d2 add.l d2,d2 add.l d0,d2 add.l d1,d2 addq.l #1,d2 lsl.l #6,d2 move.b d0,d2 move.w d2,(a1)+ Upsampling isn't very important in the final timing. The most important code is the DCT. As it's supposed to be done with this data parallelism stuff, well, it's that i want to see. Good luck without SIMD multiply. Btw 2. The parallel instructions you use here are not documented anywhere. They just come out of nowhere and i'm supposed to trust this... Btw 3. You have to understand that this SIMD stuff will only work for very simple tasks. As soon as it becomes relatively complex, it starts to fail miserably - or you'll have to create new instructions for almost everything you do. I'm not against doing things in parallel, i'm against creating new big fat registers for the sake of speed. Btw 4. This example can be rewritten by creating a simple longword parallel byte average instruction. One instruction added instead of a whole block, same timing if executed on two pipes. |
|
|
|
|
31 October 2016, 22:00
|
#13 | |||||
|
Registered User
Join Date: May 2016
Location: Rostock/Germany
Posts: 132
|
Quote:
Quote:
Quote:
Quote:
Quote:
|
|||||
|
|
|
31 October 2016, 22:31
|
#14 | |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,918
|
Quote:

|
|
|
|
|
01 November 2016, 08:41
|
#15 | ||||||
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
|
||||||
|
|
|
01 November 2016, 09:39
|
#16 | |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,918
|
Quote:
So what are your reasons? If a few ammx instructions can speed up movie replaying by a factor of two, they must be very convincing reasons. |
|
|
|
|
01 November 2016, 09:57
|
#17 | ||
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Quote:
But you can't compare. Intel throw massive amount of logic gates at every problem they face. There is also a good reason why their cpus don't go in handheld devices. Quote:
What is movie replaying anyway ? Old MPEG-1 ? You can't show youtube videos with that. Play them with your smartphone : they won't use any mmx-like extensions - they'll use a gpu. So perhaps a few ammx extensions can make better performance in a single example. One can always invent new instructions for a particular case. But next program you do, new ammx extensions will be needed. All that for a miserable x2 speed on something that's not used anymore. I have disassembled Riva and seen that this is indeed asm code, but the guy apparently "played compiler" ; it seems the original code has been followed without much refactoring. For example, the DCT shifts the result back too early after the multiplies, leading to a loss of speed (unneeded shifts) and loss of quality (reduced accuracy). There is also a lot of duplicated code (if not dead code). In short it's not exactly nice - not surprising a few code rewrite got a speedup. Again, mmx isn't needed for that. Last edited by prowler; 02 November 2016 at 21:59. Reason: Back-to-back posts merged. |
||
|
|
|
01 November 2016, 12:53
|
#18 |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,918
|
Since you know how to do it so much better: when will see your non-ammx version of the code beating the ammx-version?
|
|
|
|
01 November 2016, 13:30
|
#19 | |
|
son of 68k
Join Date: Nov 2007
Location: Lyon / France
Age: 51
Posts: 5,323
|
Quote:
Anyways the "ammx version" doesn't need my code to be beaten : Code:
4.Upload:> riva-0.50 verbose fps=1000 noskip noaudio dither=gray shk_topgun_320.mpg Video: 320x176, 24.000 fps Audio: <NONE> Number of frames played: 2143 Number of frames skipped: 0 Total number of frames: 2143 Total playback time: 13.1146 seconds. Average framerate: 163.4048 fps Displayed framerate: 163.4048 fps 4.Upload:> |
|
|
|
|
01 November 2016, 14:05
|
#20 | |
|
Registered User
Join Date: Jun 2015
Location: Germany
Posts: 1,918
|
Quote:
 BTW, the fact that you had to use the dither=gray option to make your UAE beat the 080 proves two points: AMMX is a very powerful extension to the 68k ISA and you need to buy a newer PC. Last edited by grond; 01 November 2016 at 14:26. |
|
|
|
| Currently Active Users Viewing This Thread: 1 (0 members and 1 guests) | |
| Thread Tools | |
 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| RiVA mpeg player | amiga | request.Apps | 18 | 25 February 2014 10:32 |
| ACA1231 vs M-Tec 1230 vs A630 benchmarks | alenppc | support.Hardware | 4 | 11 July 2012 18:39 |
| Some benchmarks, and a request | Damion | support.Hardware | 29 | 14 March 2011 16:10 |
| riva | amiga | request.Apps | 6 | 12 May 2008 18:56 |
| Benchmarks. | ECA | support.Hardware | 4 | 14 June 2002 15:14 |
|
|




